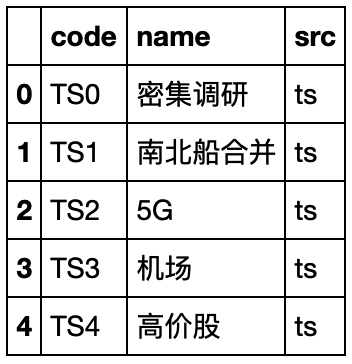
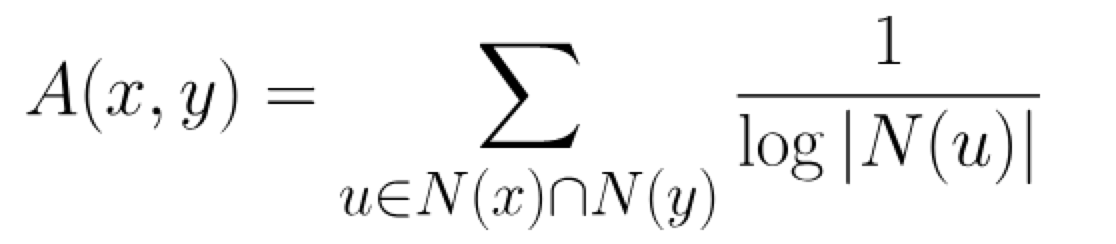import tushare as ts # 参考Tushare官网提供的安装方式 import csv import time import pandas as pd # 以下pro_api token可能已过期,可自行前往申请或者使用免费版本 pro = ts.pro_api('4340a981b3102106757287c11833fc14e310c4bacf8275f067c9b82d')
yaxis = list() for i in listdir: stock = pd.read_csv("financial_data\\price_logreturn\\"+i) yaxis.append(len(stock['logreturn'])) counts = np.bincount(yaxis)
np.argmax(counts)
3.3.2 计算股票对数收益
股票对数收益及皮尔逊相关系数的计算公式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import pandas as pd import numpy as np import os import math
listdir = os.listdir("financial_data\\price")
for l in listdir: stock = pd.read_csv('financial_data\\price\\'+l) stock['index'] = [1]* len(stock['close']) stock['next_close'] = stock.groupby('index')['close'].shift(-1) stock = stock.drop(index=stock.index[-1]) logreturn = list() for i in stock.index: logreturn.append(math.log(stock['next_close'][i]/stock['close'][i])) stock['logreturn'] = logreturn stock.to_csv("financial_data\\price_logreturn\\"+l,index=False)
from math import sqrt defmultipl(a,b): sumofab=0.0 for i inrange(len(a)): temp=a[i]*b[i] sumofab+=temp return sumofab
defcorrcoef(x,y): n=len(x) #求和 sum1=sum(x) sum2=sum(y) #求乘积之和 sumofxy=multipl(x,y) #求平方和 sumofx2 = sum([pow(i,2) for i in x]) sumofy2 = sum([pow(j,2) for j in y]) num=sumofxy-(float(sum1)*float(sum2)/n) #计算皮尔逊相关系数 den=sqrt((sumofx2-float(sum1**2)/n)*(sumofy2-float(sum2**2)/n)) return num/den
由于原始数据达百万条,为节省计算量仅选取前300个股票进行关联性分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
listdir = os.listdir("financial_data\\300stock_logreturn") s1 = list() s2 = list() corr = list() for i in listdir: for j in listdir: stocka = pd.read_csv("financial_data\\300stock_logreturn\\"+i) stockb = pd.read_csv("financial_data\\300stock_logreturn\\"+j) iflen(stocka['logreturn']) == 242andlen(stockb['logreturn']) == 242: s1.append(str(i)[:10]) s2.append(str(j)[:10]) corr.append(corrcoef(stocka['logreturn'],stockb['logreturn'])) print(str(i)[:10],str(j)[:10],corrcoef(stocka['logreturn'],stockb['logreturn'])) corrdf = pd.DataFrame() corrdf['s1'] = s1 corrdf['s2'] = s2 corrdf['corr'] = corr corrdf.to_csv("financial_data\\corr.csv")
4 搭建金融知识图谱
安装第三方库
1
pip install py2neo
4.1 基于python连接
具体代码可参考3.1 python操作neo4j-连接
1 2 3 4 5 6 7
from pandas import DataFrame from py2neo import Graph,Node,Relationship,NodeMatcher import pandas as pd import numpy as np import os # 连接Neo4j数据库 graph = Graph('http://localhost:7474/db/data/',username='neo4j',password='neo4j')
for i in concept_num.values: a = Node('概念',概念代码=i[1],概念名称=i[2]) print('概念代码:'+str(i[1]),'概念名称:'+str(i[2])) graph.create(a)
for i in stock.values: a = Node('股票',TS代码=i[1],股票名称=i[3],行业=i[4]) print('TS代码:'+str(i[1]),'股票名称:'+str(i[3]),'行业:'+str(i[4])) graph.create(a)
for i in holder.values: a = Node('股东',TS代码=i[0],股东名称=i[1],持股数量=i[2],持股比例=i[3]) print('TS代码:'+str(i[0]),'股东名称:'+str(i[1]),'持股数量:'+str(i[2])) graph.create(a)
matcher = NodeMatcher(graph) for i in holder.values: a = matcher.match("股票",TS代码=i[0]).first() b = matcher.match("股东",TS代码=i[0]) for j in b: r = Relationship(j,'参股',a) graph.create(r) print('TS',str(i[0])) for i in concept.values: a = matcher.match("股票",TS代码=i[3]).first() b = matcher.match("概念",概念代码=i[1]).first() if a == Noneor b == None: continue r = Relationship(a,'概念属于',b) graph.create(r)
noticesdir = os.listdir("notices\\") for n in noticesdir: notice = pd.read_csv("notices\\"+n,encoding="utf_8_sig") notice['content'] = notice['content'].fillna('空白') for i in notice.values: a = matcher.match("股票",TS代码=i[0]).first() b = Node('公告',日期=i[1],标题=i[2],内容=i[3]) graph.create(b) r = Relationship(a,'发布公告',b) graph.create(r) print(str(i[0])) for i in sz.values: a = matcher.match("股票",TS代码=i[0]).first() b = matcher.match("深股通").first() r = Relationship(a,'成分股属于',b) graph.create(r) print('TS代码:'+str(i[1]),'--深股通')
for i in sh.values: a = matcher.match("股票",TS代码=i[0]).first() b = matcher.match("沪股通").first() r = Relationship(a,'成分股属于',b) graph.create(r) print('TS代码:'+str(i[1]),'--沪股通')
# 构建股票间关联 corr = pd.read_csv("corr.csv") for i in corr.values: a = matcher.match("股票",TS代码=i[1][:-1]).first() b = matcher.match("股票",TS代码=i[2][:-1]).first() r = Relationship(a,str(i[3]),b) graph.create(r) print(i)
5 数据可视化查询
基于Crypher语言,以平安银行为例进行可视化查询。
5.1 查看所有关联实体
1
match p=(m)-[]->(n) where m.股票名称="平安银行" or n.股票名称="平安银行" return p;
5.2 限制显示数量
计算股票间对数收益率的相关系数后,查看与平安银行股票相关联的实体
1
match p=(m)-[]->(n) where m.股票名称="平安银行" or n.股票名称="平安银行" return p limit 300;
5.3 指定股票间对数收益率相关系数
1
match p=(m)-[]->(n) where m.股票名称="平安银行" and n.股票名称="万科A" return p;
// 计算 Michael 和 Karin 之间的亲密度 MATCH (p1:Person {name: 'Michael'}) MATCH (p2:Person {name: 'Karin'}) RETURN algo.linkprediction.adamicAdar(p1, p2) AS score // score: 0.910349
// 基于好友关系计算 Michael 和 Karin 之间的亲密度 MATCH (p1:Person {name: 'Michael'}) MATCH (p2:Person {name: 'Karin'}) RETURN algo.linkprediction.adamicAdar(p1, p2, {relationshipQuery: "FRIENDS"}) AS score // score: 0.0