概述:Rabbitmq & Celery
[TOC]
Rabbitmq & Celery
一、Rabbitmq
1.安装
以mac OS为例:
(1)安装Homebrew [已安装可忽略]
1 | ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" |
(2)通过brew安装Rabbitmq
1 | brew install rabbitmq |
(3)环境变量
1 | vi /etc/profile |
2.基础概念
(1)高级消息队列协议(Advanced Message Queueing Protocol, AMQP)是面向消息中间件的开放标准应用程序层协议。
(2)在AMQP中,发送消息的应用程序(称为生产者)将消息发布到AMQP代理,该代理将消息分发给处理消息的应用程序(消费者)。
(3)AMQP 消息队列服务器实体(Broker)的内部结构主要包括三种实体,分别是交换器(Exchange)、队列(Queue)、绑定(bindings),如下图:
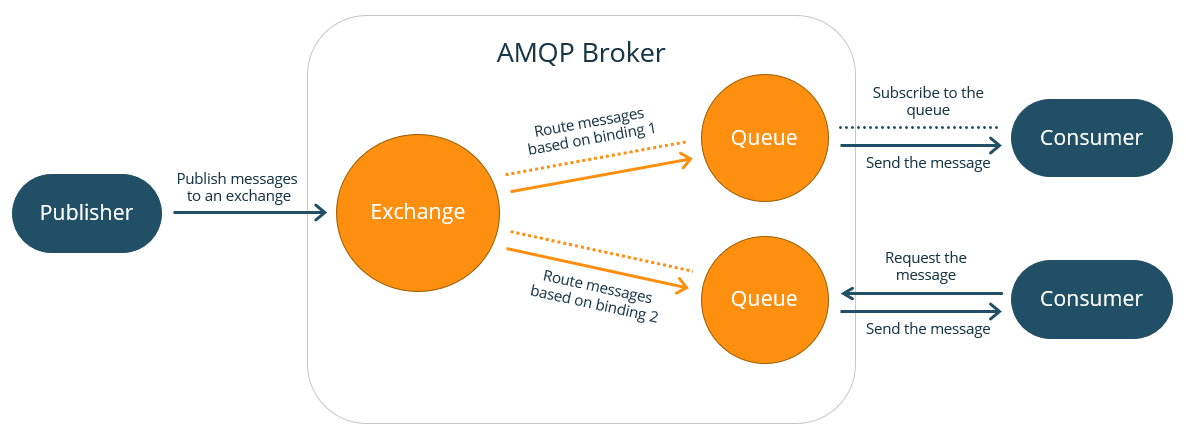
其中bingings是指将Exchange和Queue按路由规则绑定。
(4)Exchange分发消息时根据类型的不同分发策略有区别,目前共三种类型:direct、fanout、topic。
direct
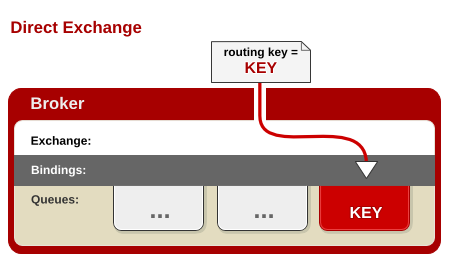
消息中的路由键(routing key)如果和 Binding 中的 binding key 一致, 交换器就将消息发到对应的队列中。路由键与队列名完全匹配,如果一个队列绑定到交换机要求路由键为“dog”,则只转发 routing key 标记为“dog”的消息,不会转发“dog.puppy”,也不会转发“dog.guard”等等。它是完全匹配、单播的模式。
应用场景:现在我们考虑只把重要的日志消息写入磁盘文件,例如只把 Error 级别的日志发送给负责记录写入磁盘文件的 Queue。这种场景下我们可以使用指定的 RoutingKey(例如 error)将写入磁盘文件的 Queue 绑定到 Direct Exchange 上。
fanout
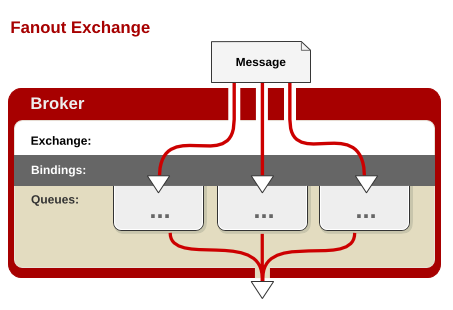
每个发到 fanout 类型交换器的消息都会分到所有绑定的队列上去。fanout 交换器不处理路由键(没有路由键概念),只是简单的将队列绑定到交换器上,每个发送到交换器的消息都会被转发到与该交换器绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。fanout 类型转发消息是最快的,也实现了一个消息被多个消费者获取的需求。
应用场景:以日志系统为例:假设我们定义了一个 Exchange 来接收日志消息,同时定义了两个 Queue 来存储消息:一个记录将被打印到控制台的日志消息;另一个记录将被写入磁盘文件的日志消息。我们希望 Exchange 接收到的每一条消息都会同时被转发到两个 Queue,这种场景下就可以使用 Fanout Exchange 来广播消息到所有绑定的 Queue。
topic
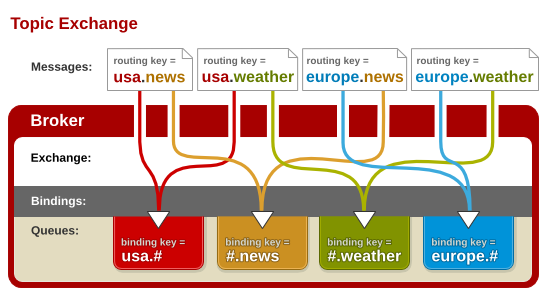
topic 交换器通过模式匹配分配消息的路由键属性,将路由键和某个模式进行匹配,此时队列需要绑定到一个模式上。它将路由键和绑定键的字符串切分成单词,这些单词之间用点隔开。它同样也会识别两个通配符:符号“#”和符号“”。#匹配0个或多个单词,匹配不多不少一个单词。
应用场景:假设我们的消息路由规则除了需要根据日志级别来分发之外还需要根据消息来源分发,可以将 RoutingKey 定义为 消息来源.级别 如 order.info、user.error等。处理所有来源为 user 的 Queue 就可以通过 user.* 绑定到 Topic Exchange 上,而处理所有日志级别为 info 的 Queue 可以通过 *.info 绑定到 Exchange上。
3.常见命令
(1)启动服务
1 | rabbitmq-server |
(2)查看状态
1 | rabbitmqctl status |
(3)访问
1 | http://localhost:15672 |
(4)停止服务
1 | rabbitmq-service stop |
(5)查看所有队列
1 | rabbitmqctl list_queues |
(6)清除所有的队列
1 | rabbitmqctl reset |
(7)添加用户
1 | rabbitmqctl add_user username password |
(8)分配角色
1 | rabbitmqctl set_user_tags username administrator |
(9)新增虚拟主机
1 | rabbitmqctl add_vhost vhost_name |
4.Hello Rabbitmq
Hello World将展示生产者传输数据至消息队列,消费者从消息队列中取数据的过程,类似于下图:

其中P表示生产者,C表示消费者,红色矩阵表示消息队列,hello表示传输的数据。
(1)生产者
send.py
1 | import pika |
(2)消费者
receive.py
1 | import pika |
- 执行
receive.py - 执行2次
send.py后,查看队列,会发现Ready=2:

- 查看消费者的终端输出
1 | 正在等待接收消息,退出请按CTRL+C …… |
5.问题记录
(1)消费者接收异常
1 | channel.basic_consume(callback, queue=queue, no_ack=False) |
版本更新导致参数位置和参数名称均涉及更新:
1 | channel.basic_consume(queue=queue, on_message_callback=callback,auto_ack=True) |
(2)启动过程异常
1 | zsh: command not found: rabbitmq-server |
编辑~/.zshrc并写入以下3行配置
1 | vim ~/.zshrc |
(3)启动过程异常
1 | Configuring logger redirection |
解决: sudo rabbitmq-server
(3)启动失败
zsh: command not found: rabbitmq-server
编辑~/.zshrc并写入以下3行配置
1 | vim ~/.zshrc |
(4)安装相关异常
(1)问题:执行sudo make test编译过程可能报错
解决方案:执行命令清理再编译:sudo make distclean && sudo make && sudo make test
(2)问题:安装Redis的编译过程出现问题“Failed opening the RDB file dump.rdb (in server root dir /usr/local/redis-6.0.5) for saving: Permission denied”,说明未赋予权限,需要对所安装的redis目录给予777权限:
解决方案:sudo chmod -R 0777 redis-6.0.5
二、Celery
1.模块架构
| M1 | M2 | M3 | ||
|---|---|---|---|---|
| Async Task 异步任务 Producer 任务发布者 |
发送➡️ | ⬅️监控 | Worker 任务消费者 | |
| Celery Beat 任务调度/定时任务 | 发送➡️ | Broker消息代理 | ⬅️监控 | Worker 任务消费者 |
| ⬇️ 存储 | ||||
| Backend 结果存储 |
Celery模块:
- 定时任务/任务调度 Celery Beat
读取配置文件的内容,周期性地将配置中到期需要执行的任务发送给任务队列。
- 任务模块 Task
包含异步任务和定时任务,其中异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由 Celery Beat 进程周期性地将任务发往任务队列,通常由Producer(任务生产者)产生任务交给任务队列。
- 消息中间件 / 消息代理 Broker
Broker,即为任务调度队列,接收任务生产者发来的消息(即任务),将任务存入队列。Celery 本身不提供队列服务,官方推荐使用 RabbitMQ 和 Redis 等。
- 任务执行单元/ 任务消费者 Worker
Worker 是执行任务的处理单元,它实时监控消息队列,获取队列中调度的任务,并执行它。
- 任务结果存储 Backend
Backend 用于存储任务的执行结果,以供查询。同消息中间件一样,存储也可使用 RabbitMQ, Redis 和 MongoDB 等。
2.基本概念
任务生产者 (task producer) 负责产生计算任务,交给任务队列去处理。
任务调度器 (celery beat)会读取配置文件的内容,周期性地将执行任务的请求发送给任务队列。
任务代理 (broker)负责接受任务生产者发送过来的任务处理消息,存进队列之后再进行调度,分发给任务消费方 (celery worker)。
任务消费方 (celery worker)负责接收任务处理中间方发来的任务处理请求,完成这些任务,并且返回任务处理的结果。
Result Backend:任务处理完后保存状态信息和结果,以供查询。Celery默认已支持Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy等方式。
3.Hello Celery
(1)安装
1 | pip install celery==4.4.7 |
Tip:celery( v5.0.0 )存在缺陷——backend找不到amqp
(2)创建celery应用
tasks.py
1 | from celery import Celery |
(3)启动worker
tasks为工程名
1 | celery -A tasks worker --loglevel=INFO [-Q QUEUE_NAME] |
(4)调用application
触发消息提交至队列
1 | python |
调用(4)后可查看Terminals的worker相关信息输出
(5)查看执行结果
1 | result.result |
(6)使用config加载Celery信息
除了上述app = Celery('tasks', broker='amqp://guest:guest@127.0.0.1:5672')的方法外,还可以将Celery的配置存入celeryconfig.py文件中,使用app.config_from_object加载:
tasks.py
1 | from celery import Celery |
celery_config.py
1 | from datetime import timedelta |
4.在Django中使用信号量
信号量(Signal):在特定事件发生时,可以发送一个信号去通知注册了这个信号的一个或者多个回调,在回调里进行逻辑处理。
(1)自定义信号量
event.py
1 | from django.dispatch import Signal # 内置库 |
(2)加载信号量 - 绑定处理函数
__init__.py
1 | from .event import mySignal |
apps.py
1 | from django.apps import AppConfig # 内置库 |
(3)事件触发 - send
view.py
1 | from .event import mySignal |
(4)接收信号 + 执行(signals.py处理信号的函数)
1 | from django.dispatch import receiver # 内置库 |
(5)celery内置的几种信号
from celery.signals import before_task_publish, task_postrun
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
after_task_publish - sender 发布 task 之后。
task_prerun - receiver 执行 task 之前。
task_postrun - receiver 执行 task 之后。
task_retry - receiver 执行 task 时,发生「重试」。
task_success - receiver 执行 task 时,发生「成功」。
task_failure - receiver 执行 task 时,发生「失败」。
task_revoked - receiver 执行 task 时,发生「注销」。
task_unknown - receiver 无法辨识。当 project 和 celery 的 task 产生落差时,会发生的状况。
补充:before_task_publish提供了很多参数:任务消息体body、交换器exchange、路由键routing_key、应用头部映射headers、消息属性properties、实体列表declare、重试策略retry_policy。(具体描述可参考官网)
其中 headers = {'lang': 'py', 'task': 'tasks.add', 'id': '15856ead-8a38-4a65-95d5-9baffc3c301c', 'shadow': None, 'eta': None, 'expires': None, 'group': None, 'group_index': None, 'retries': 0, 'timelimit': [None, None], 'root_id': '15856ead-8a38-4a65-95d5-9baffc3c301c', 'parent_id': None, 'argsrepr': '[1, 200]', 'kwargsrepr': '{}', 'origin': 'gen29622@JUNMINGGUO-MB0'}
补充: ETA(estimated time of arrival, 预计到底时间)让你设置一个日期和时间,在这个时间之前任务将被执行。 countdown 是一种以秒为单位设置ETA的快捷方式。 确保任务在指定的日期和时间之后的某个时间执行,但不一定在该时间执行。
(6)django内置的几种信号
from django.db.models.signals import pre_save,post_save
1 | pre_save - models对象保存之前触发 |
(7)自动收集异步任务
1 | app = Celery('CELERY_NAME') |
(8)使用日志记录
1 | from celery.utils.log import get_task_logger |
5.任务调度器(Beat)
(1)配置
在celeryconfig.py中配置CELERYBEAT_SCHEDULE:
1 | CELERYBEAT_SCHEDULE = { |
(2)启动周期性任务
任务调度器会周期性(3秒)地启动任务,将需要执行的任务发送给任务队列。
1 | celery -A YOUR_TASK_NAME beat --loglevel=INFO [-Q QUEUE_NAME] |
(3)查看周期性任务
1 | celery -A YOUR_TASK_NAME worker --loglevel=INFO [-Q QUEUE_NAME] |
6.Django-setting其它相关配置
(1)异步任务绑定自定义任务队列名
1 | from kombu import Queue, Exchange |
(2)周期性任务
1 | CELERY_BEAT_SCHEDULE={ |
实践
1.安装celery
2.安装rabbitmq
3.实践celery + rabbitmq
1 | from celery import Celery |
4.运行celery
1 | celery -A tasks worker --loglevel=INFO |
5.查看完整的命令行参数列表
1 | celery worker --help |
6.调用任务:使用delay()调用任务,是apply_async()的快捷方式
1 | from tasks import add |
三、Celery_once
1.作用
可防止Celery重复执行相同任务,即避免队列中存在重复异步任务。
2.安装
1 | pip install celery_once |
3.实现原理
采用redis分布式锁,重写了Celery的apply_async(),重写的源码:
1 | def apply_async(self, args=None, kwargs=None, **options): |
重点内容在于:
1 | if not options.get('retries'): |
(1)try中去判断队列中是否存在(尝试加锁进行判断),若加锁失败则表示队列中存在相同异步任务,因而触发except AlreadyQueued,如果once_graceful=True则表示不抛错,反之设为False则raise e。
(2)注意到如果触发AlreadyQueued时会返回EagerResult对象,其中它的__init__:
1 | def __init__(self, id, ret_value, state, traceback=None): |
原因在于Celery启动周期性任务Beat时,会触发celery/beat.py中的apply_entry方法,源码:
1 | def apply_entry(self, entry, producer=None): |
分析可知,apply_entry中会获取apply_async的返回结果赋给result,其中发布异步任务失败(当队列中存在相同任务时),会进入else分支,而该部分需要获取result.id,所以EagerResult中需要赋予id字段为None,从而避免触发NoneType has not key ‘id’,而其它字段为可选字段,例如_state,_traceback等。
4.备注
Celery_once实现原理采用的redis共享锁,因此中间件(broker)仅支持redis,不支持其它broker,例如rabbitmq。
1 | CELERY_ONCE = { |
四、Flower-Celery
Flower-Celery是一款Celery的监控可视化工具
1.安装
1 | pip install flower |
2.启动
1 | flower -A tasks --port=5555 |
3.访问
4.可视化展示
